pdxhash: an implementation of #pdxtags using the geohash algorithm
 I never learned about geohashes in school, but I ran across the term when I was figuring out how to do fast GIS operations in the Google App Engine cloud computing platform. It is a two way function that encodes a latitude and longitude into a 20 character string. According to the wikipedia page, a geohash could be a possible geotagging implementation. I've found that using a geohash you can split the Portland area into 15 unique zones each identified by a four characters.
I thought that maybe we could use a geohash to geotag locations in Portland as specified in the #pdxtags civicapp idea submission. Geohashes are accurate approximately 79% of the time, all the time. They actually do have trouble around the international date line, but we don't care about anywhere beyond Portland.
A geohash is made up of a string of 20 letters or numbers. As you go from left to right, the area of the earth that is specified gets smaller and the precision of the location increases. Because of that characteristic we can throw away most of the characters.
When grouped by geohash, it turns out that you can slice up the Portland area into 15 polygons, each of which can be identified by a 4 character string. Here is the address point dataset organized into these groups.
I never learned about geohashes in school, but I ran across the term when I was figuring out how to do fast GIS operations in the Google App Engine cloud computing platform. It is a two way function that encodes a latitude and longitude into a 20 character string. According to the wikipedia page, a geohash could be a possible geotagging implementation. I've found that using a geohash you can split the Portland area into 15 unique zones each identified by a four characters.
I thought that maybe we could use a geohash to geotag locations in Portland as specified in the #pdxtags civicapp idea submission. Geohashes are accurate approximately 79% of the time, all the time. They actually do have trouble around the international date line, but we don't care about anywhere beyond Portland.
A geohash is made up of a string of 20 letters or numbers. As you go from left to right, the area of the earth that is specified gets smaller and the precision of the location increases. Because of that characteristic we can throw away most of the characters.
When grouped by geohash, it turns out that you can slice up the Portland area into 15 polygons, each of which can be identified by a 4 character string. Here is the address point dataset organized into these groups.
select substring(trim(ST_Geohash(wkb_geometry)) from 0 for 5) as pdx_hash, count(*) as address_point_count from address_data group by pdx_hash order by address_point_count;
pdx_hash | address_point_count ----------+--------------------- c211 | 2 c207 | 2 c217 | 3 c209 | 12 c20c | 14 c20b | 14 c206 | 54 c20s | 157 c215 | 507 c214 | 1263 8xj2 | 14008 c20e | 23581 c20d | 24980 c20g | 94659 c20f | 156877 (15 rows)Beyond that, you can further subdivide Portland into 108 zones which can be uniquely identified by a 5 letter string. It is easy to control how accurately a tagged location is identified by using more or less characters. A 5 letter pdx_hash is more accurately described than one with 4 letters. With a 6 character pdx_hash you get 1487 different zones at higher resolution. When you look at the count of address point in each polygon, it becomes apparent that the bulk of Portland addresses fall into the same five or six zones. One advantage to this method is that geohash is not subject to any claim of copyright or corporate control. The algorithm is public domain and open to use by anyone. It would be reasonable for the city to eventually add a pdx_hash to all street signs allowing people to figure out the geotag of their current location without smartphones. Later, I'll post some maps as well as do some error analysis. In the course of working with the address point data, I found a simple way to load csv files into postgis, which I will also post about. The examples in this post were done in Postgis, but you should also be able to use the same query in Microsoft SQL Server 2008 and Oracle. Although the string manipulation might be a little different.
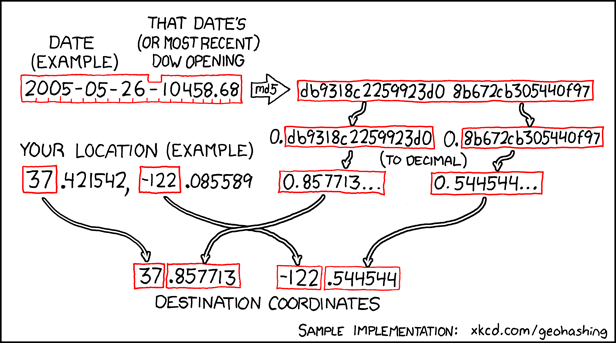
The web comic xkcd is where I think most of us first heard about geohashing. ;)